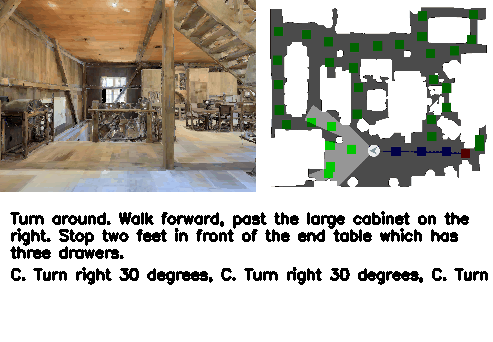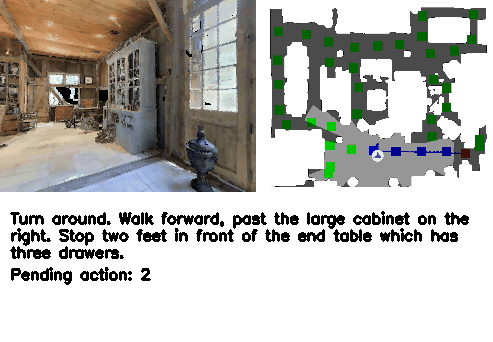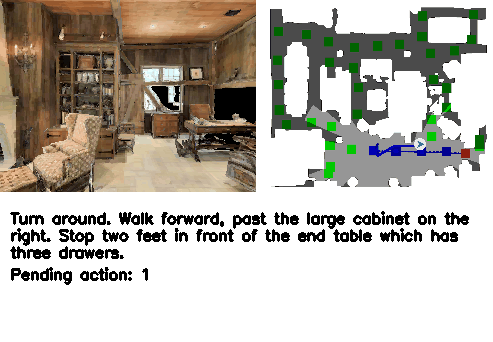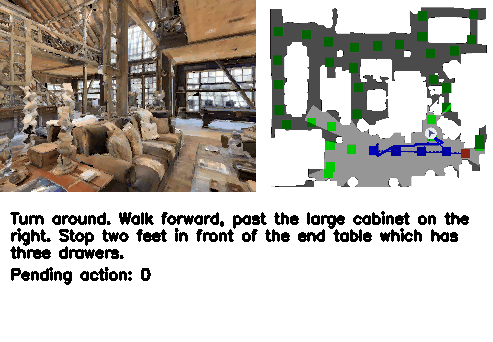
Abstract
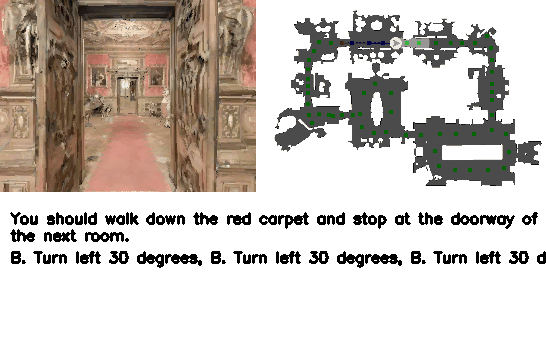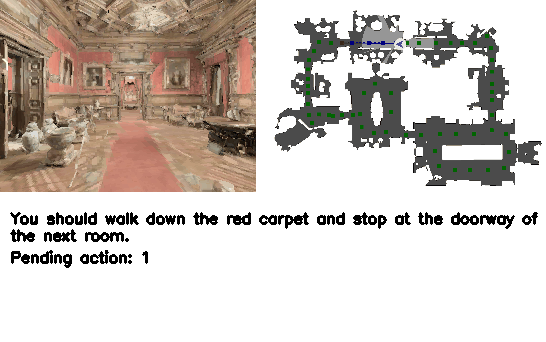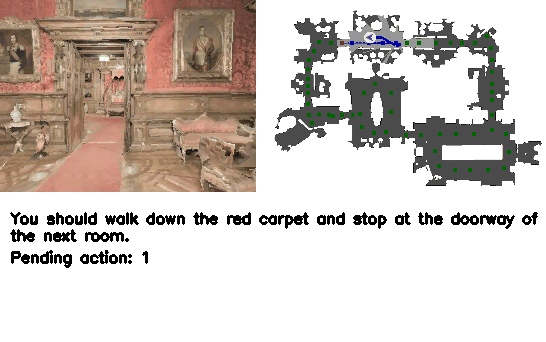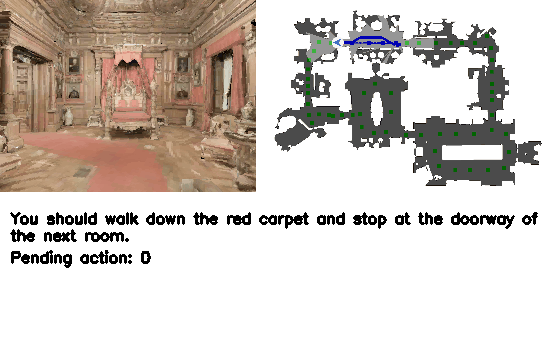
Vision-Language Navigation (VLN) is a core challenge in embodied AI, requiring agents to navigate real-world environments using natural language instructions. Current language model-based navigation systems operate on discrete topological graphs, limiting path planning to predefined node connections. We propose VLN-R1, an end-to-end framework that leverages Large Vision-Language Models (LVLM) to directly translate egocentric video streams into continuous navigation actions, adopting GRPO-based training inspired by DeepSeek-R1.
To enable effective training, we first construct the VLN-Ego dataset using a 3D simulator, i.e., Habitat, and propose Long-Short Memory Sampling to balance historical and current observations. While large language models can supervise complete textual instructions, they lack fine-grained action-level control.
Our framework employs a two-stage training approach: a) Supervised fine-tuning (SFT) to align the model's action sequence text predictions with expert demonstrations, followed by b) Reinforcement fine-tuning (RFT) enhanced with a Time-Decayed Reward (TDR) mechanism that strategically weights multi-step future actions.
Experimental results show VLN-R1 achieves strong performance on the VLN-CE benchmark. VLN-R1 proves LVLMs can drive embodied navigation and enhance task-specific reasoning through data-efficient, reward-driven post-training.